ai-toolbox
deep dive into applications and algorithms
Reduce energy and amount of IPA in the process industry
AI application and implementation to optimize manufacturing process in line of organic products, reducing waste and energy consumption
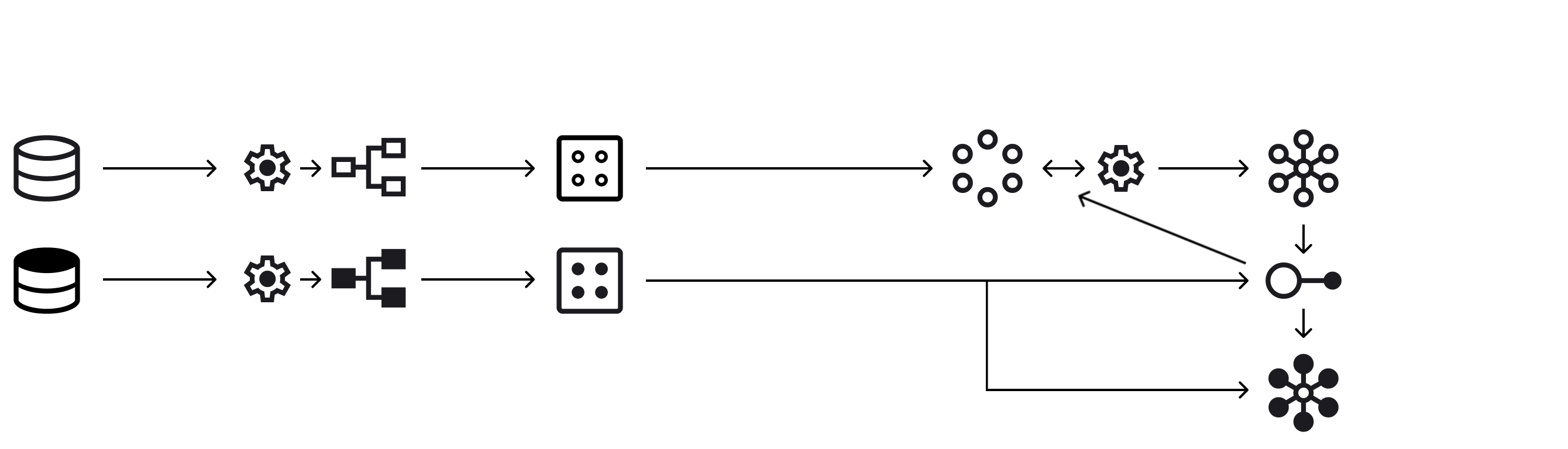 Production Data
Testing Data
Production Data
Testing Data
Raw Data - Training
Data from manufacturing process using PLCs, energy meters and other sensors like temperature.
- The data was extracted thought connection to server via the CEAMSA VPN. AIMEN fixed the initial data, the end date and the variable of interest through the CEAMSA platform. After that AIMEN submitted the pertinent request.
- For each variable, AIMEN received a file in a JSON format containing the value of the variable every minute from the initial date until the end date
Raw Data - Testing/Production
Preprocessing - Training Data
- Data collection: Collect data on manufacturing process using PLCs, energy meters and other sensors like temperature.
- Data analysis: Analyse the process collected data (temperature, flow, level…) to identify areas where energy consumption can be optimized and determine the factors that affect process efficiency
- Model: Create a specific dataset describing the manufacturing process using historical data and analysis tools.
- Optimization: Use AI over the dataset to run simulations and identify ways to optimize energy consumption, such as adjusting process parameters or using more efficient equipment (pumps, heaters, tanks isolations, ...).
- Implementation: Implement the changes identified and monitor the results to ensure that they are effective.
- Continuous improvement: Continuously monitor the manufacturing process to identify new opportunities for optimization and update the optimizer accordingly
Preprocessing - Testing/Production Data
Dataset - Training
Dataset - Testing/Production
Model Training
Trained Model
Learn moreModel Testing
Tested Model
Motivation
To apply and implement AI to optimize manufacturing process in line of organic products (Synthesis and exTractions), reducing waste and energy consumption. By providing a decision-support tools to employees, the company will have a more resilient and agile plant to internal (shop-floor machinery conditions) and external changes (raw organic material).
Objective
Main objective is to develop an automated decision-making system for optimal adjustment of process parameters to reduce energy consumption, in order to comply with CEAMSA principles/increase competitiveness/preserve production in Europe.
Use of AI
To optimize IPA (isopropyl alcohol) consumption and therefore thermal energy consumption in an extraction manufacturing process, a data-driven approach using machine learning (AI-ML) algorithms is required.
For the automatic process adjustment it is needed to extract the knowledge and experience of the operators and transform it into rules for which we use AI tools such as multi-arm bandit, and a Markov decision process.
Service reciever company
CEAMSA
https://www.ceamsa.com/Description
CEAMSA (Compañía Española de Algas Marinas) is a Spanish company founded in 1966 that specializes in producing natural hydrocolloids like carrageenan, pectin, alginate, fibre, and locust bean gum. These ingredients are used for gelling, thickening, and stabilizing in food, pharmaceutical, and cosmetic industries. CEAMSA is known for its innovation, sustainability, and global distribution from its headquarters in Porriño, Spain

Service provider company
AIMEN
https://www.aimen.es/enDescription
AIMEN is a Spanish non-profit technology centre focused on advanced manufacturing and materials science. It supports over 500 companies with R&D, innovation, and high-tech services in areas like laser processing, robotics, and automation. Its mission is to drive industrial competitiveness through cutting-edge technological solutions.
Project Results
The AI-developed decision-support system is now able to provide optimal values to perform the optimal automatic control of the IPA ratio management in the pectin extraction process. The system consists of a set of interrelated tanks and machines in which the operator previously had to make adjustments in order to optimize the precipitation process and reduce IPA and energy consumption. With the help of AI and the new system, CEAMSA can automate the control and thus standardize the management process, avoiding operator dependency and balancing production and sustainability.
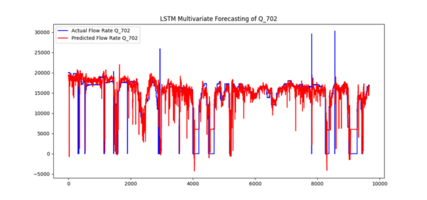
The LSTM predictive model demonstrates a solid ability to learn and reproduce the temporal dynamics of the CEAMSA process data. After training on 80 % of the available time-series and testing on the remaining 20 %, the model achieves low prediction error when evaluated using Mean Squared Error (MSE), indicating that the forecasted flow rate closely follows the true measured values. The learning curves show stable convergence with no signs of overfitting, confirming that the model generalizes well to unseen process conditions. Visual inspection of predicted versus actual time series further supports the model’s reliability. Predictions capture both short-term fluctuations and longer-term trends, which validates the suitability of the LSTM architecture for this kind of industrial sequential data.
Overall, the model performs accurately and consistently, providing a robust foundation for process monitoring or control applications. Its performance could be further enhanced by fine-tuning hyperparameters (e.g., sequence length, hidden-layer size), incorporating additional contextual features such as temperature or pressure, and evaluating complementary error metrics like MAE or R2R^2R2 to quantify goodness of fit in more interpretable terms.
Thanks to that, it was estimated a saving of 4% of thermal energy consumed per Kg produced.
Additional achievements:
- Improve the sustainability of processes and products, significantly reduce energy consumption and lower the energy and carbon footprint
- Make industrial processes more agile, secure and resilient to future changes:
- Make manufacturing jobs more attractive for humans, whichever the age, gender or social and cultural background, through better human-machine interfaces and more intuitive interaction with digital tools
Figures
Data
Raw Data
Raw data description
- The JSON file was converted to a CSV file containing only the time and the variable's values. The data was normalized with MinMax standardization.
- At the end 6 features were given as inputs to the model for predicting one feature:
- The flow rate Q_701: the flow rate of the product injected into the process.
- The flow rate Q_706: an amount of alcohol injected during the process and that will affect the IPA in the Tank 702
- The flow rate Q_733: an amount of alcohol injected during the process and affects the value of the IPA
- The IPA: it is a parameter calculated from the density of alcohol in the Tank 702 depending on the temperature and other environment parameters.
- The density 706: the density of the alcohol injected through the tube 706.
- The density 733: the density of the alcohol injected through the tube 733.
- Relevant algorithms
- LSTM (Long Short-Term Memory) is a type of recurrent neural network designed to capture long-term dependencies in sequential data. In time series forecasting, LSTM learns patterns and trends over time, making it effective for predicting future values even when past observations have complex temporal relationships. The algorithm
- Resulting features after pre-processing
- flow rate Q_702| float | the flow rate Q_702 represents the feature that affects the IPA of the Tank 702. So, the solution predicts the flow rate Q_702 from the features given as input when the IPA is fixed to 70. Which represents the flow rate of the dirty alcohol that gets out from the Tank 702, divided by the flow rate Q_701 of the product, reinjected into the machine and restarts a new cycle.
Data preprocessing
Raw Data
Data preprocessing
Trained model/s
Model selection
- The predictive model implemented is a Long Short-Term Memory (LSTM) neural network, a recurrent architecture well-suited for modeling sequential and time-dependent data. LSTMs are particularly effective for capturing long-term dependencies in time series, making them appropriate for predicting flow rate dynamics in the CEAMSA process.
- The LSTM architecture was chosen due to its proven capability to learn temporal patterns and nonlinear relationships in industrial process data. Unlike classical regression or shallow neural networks, LSTMs can retain relevant information across long sequences, which is essential for accurately forecasting the flow rate Q_702 based on the historical behavior of correlated variables such as flow rates, densities, and IPA levels.
- The model was trained from scratch using CEAMSA-specific process data. No external pretrained model was used, as the industrial dataset and feature space are domain-specific and not compatible with standard pretrained time-series models
- The preprocessed dataset was divided into 80% training data and 20% test data. Training data were fed to the model in sequences of 30 time steps, each containing the six normalized input features. The model was trained to predict the target variable Q_702 under the condition that the IPA in Tank 702 remains fixed at 70. The Adam optimizer was employed for gradient-based optimization.
- The model minimized the Mean Squared Error (MSE) between the predicted and true normalized values of Q_702, as this metric effectively penalizes large deviations and supports continuous regression outputs.